
Introduction to Couchbase - NoSQL Document Database
Abstract
Nowadays the market is full of terms like NoSQL, Big Data or NewSQL. Often, IT decision makers can get very confused with all the noise. Why should anybody consider a newer, alternative database when RDBMSs have been around for more than 2 decades? However, many leading enterprises are already using alternative databases and are saving money, innovating faster, and completing projects they could not pursue before as a result. The purpose of this article is to provide an overview of one particular NoSQL technology - Couchbase Document Database. You’ll find the reasons for choosing this technology and in what kind of projects it is being used in.
Why NoSQL?
Choosing the most appropriate technology based on requirements is an important decision from the architectural point of view. When making a decision about the type of the storage to use, there are several aspects to consider.
Nature of data
If the data has a simple tabular structure, like an accounting spreadsheet, then the relational model could be adequate. On the other hand, complex data with multiple nested levels is not very easy to fit into a two-dimensional row-column structure. In such cases, we should consider using NoSQL databases, where this kind of data structures can be represented using JSON format used by some NoSQL products.
Another aspect to consider is the volatility of the data model. An important question to answer is how often will the data model change and evolve? Most of the time, during design phase, the data model is not known and flexibility is required. The schema-rigidity is one of possible issues with RDBMS.
Application development
Nowadays, developers require high coding velocity and great agility in the application building process. In that regard, NoSQL technologies have proven to be a better choice. Using JSON format for modeling data allows developers to build prototypes in very short time.
Operational issues
As a database grows and the number of users increases, many RDBMS-based sites suffer from performance issues. Most of the time, the solution is to scale vertically (at high cost).
On the other hand, NoSQL technologies were designed specifically to address scalability (horizontal) and performance issues.
Data warehousing and analytics
RDBMS are well suited for complex querying, reporting and analysis. It is still a good choice when query and reporting needs are critical. Real-time analytics for operational data is better suited for the NoSQL setting.
What is Couchbase
Couchbase Server is a NoSQL document database for interactive web applications. It has a flexible data model, is easily scalable, provides consistent high performance and is capable of serving application data with 100% uptime.
Couchbase is the merge of two popular NOSQL technologies:
- Membase, which provides persistence, replication, sharding to the high performance memcached technology
- CouchDB, which pioneers the document oriented model based on JSON
Main Features
Flexible data model
With Couchbase Server, JSON documents are used to represent application objects and the relationships between objects. This document model is flexible enough so that you can change application objects without having to migrate the database schema, or plan for significant application downtime. The other advantage of the flexible, document-based data model is that it is well suited to representing real-world items. JSON documents support nested structures, as well as fields representing relationships between items which enable you to realistically represent objects in your application.
Easy scalability
It is easy to scale with Couchbase Server, both within a cluster of servers and between clusters at different data centers. You can add additional instances of Couchbase Server to address additional users and growth in application data without any interruptions or changes in application code. With one click of a button, you can rapidly grow your cluster of Couchbase Servers to handle additional workload and keep data evenly distributed. Couchbase Server provides automatic sharding of data and rebalancing at run time; this lets you resize your server cluster on demand.
Easy developer integration
Couchbase provides client libraries for different programming languages such as Java / .NET / PHP / Ruby / C / Python / Node.js
For read, Couchbase provides a key-based lookup mechanism where the client is expected to provide the key, and only the server hosting the data (with that key) will be contacted.
Couchbase also provides a query mechanism to retrieve data where the client provides a query (for example, a range based on some secondary key) as well as the view (basically the index). The query will be broadcast to all servers in the cluster and the result will be merged and sent back to the client.
For write, Couchbase provides a key-based update mechanism where the client sends an updated document with the key (as doc id). When handling write request, the server will respond to client’s write request as soon as the data is stored in RAM on the active server, which offers the lowest latency for write requests.
Consistent high performance
Couchbase Server is designed for massively concurrent data use and consistently high throughput. It provides consistent sub-millisecond response times which help ensure an enjoyable experience for application users. By providing consistent, high data throughput, Couchbase Server enables you to support more users with fewer servers. Couchbase also automatically spreads the workload across all servers to maintain consistent performance and reduce bottlenecks at any given server in a cluster.
Reliable and secure
Couchbase support access control using username and passwords. The credentials are transmitted securely over the network. The sensitive data can be protected while it is transmitted to/from the client application.
There is no single point of failure, since the data can be replicated across multiple nodes. Features such as cross-data center replication, failover, and backup and restore help ensure availability of data during server or datacenter failure.
Core Concepts
Couchbase as Document Store
The primary unit of data storage in Couchbase Server is a JSON document, which makes your application free ofrigidly-defined relational database tables. Because application objects are modeled as documents, schema migrations do not need to be performed.
The binary data can be stored in documents as well, but using JSON structure allows the data to be indexed and queried using views. Couchbase Server provides a JavaScript-based query engine to find records based on field values.
Data Buckets
The data is stored in a Couchbase cluster using buckets. Buckets are isolated, virtual containers which logically group records within a cluster. A bucket is the equivalent of a database. They provide a secure mechanism for organizing, managing and analyzing data storage.
Documents are distributed uniformly across the cluster and stored in the buckets. Buckets provide a logical grouping of physical resources within a cluster. More specifically, it is possible to configure the memory for caching data or number of replicas per each bucket.
vBuckets
A vBucket is defined as the owner of a subset of the key space of a Couchbase cluster. The vBucket system is used both for distributing data across the cluster and for supporting replicas on more than one node.
Every document ID belongs to a vBucket. A mapping function is used to calculate the vBucket in which a given document belongs. In Couchbase Server, that mapping function is a hashing function that takes a document ID as input and outputs a vBucket identifier. Once the vBucket identifier has been computed, a table is consulted to lookup the server that “hosts” that vBucket. The table contains one row per vBucket, pairing the vBucket to its hosting server. A server can be responsible for multiple vBuckets.
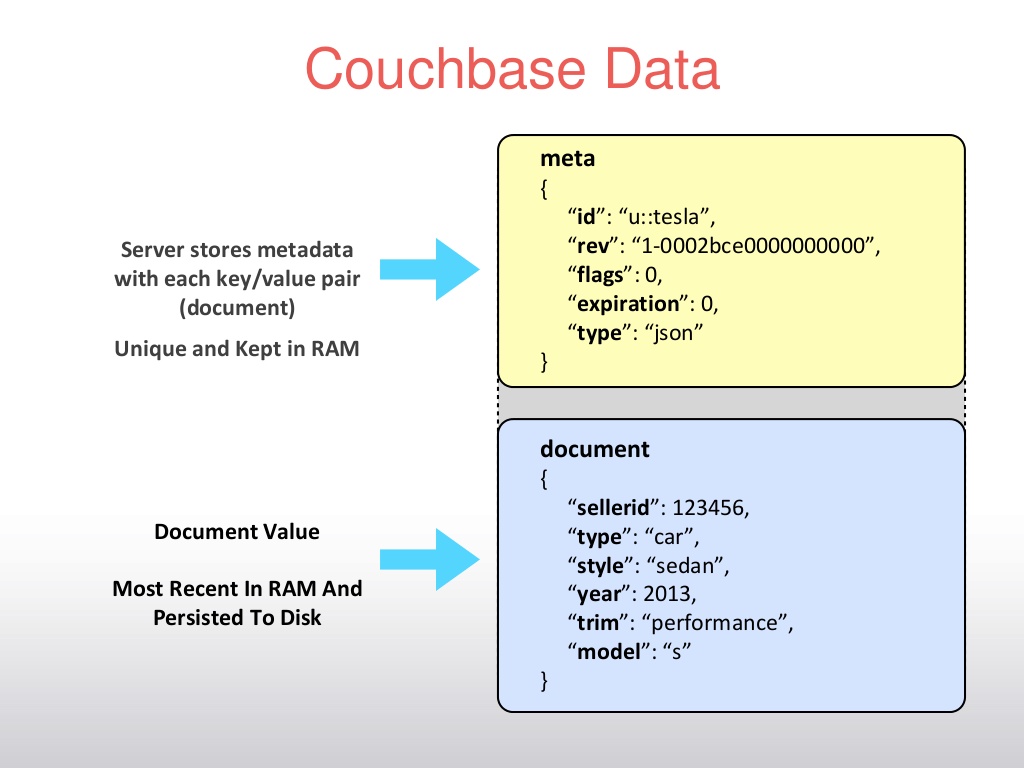
Keys and metadata
All information stored in Couchbase Server are documents with keys. Keys are unique identifiers of documents, and values can be either JSON documents or byte streams, data types, or other forms of serialized objects.
Keys are also known as document IDs and serve the same function as a SQL primary keys. A key in Couchbase Server can be any string. A key is unique.
By default, all documents contain three types of metadata. This information is stored with the document and is used to change how the document is handled:
- CAS Value - a form of basic optimistic concurrency.
- Time to Live (ttl) — expiration for a document (seconds)
- Flags - A variety of options during storage, retrieval, update, and removal of documents.
Couchbase SDK
Couchbase SDKs (aka client libraries) are the language-specific SDKs provided by Couchbase. A Couchbase SDK is responsible for communicating with the Couchbase Server and provides language-specific interfaces required to perform database operations.
All Couchbase SDKs automatically read and write data to the right node in a cluster. If database topology changes, the SDK responds automatically and correctly distributes read/write requests to the right cluster nodes. Similarly, if your cluster experiences server failure, SDKs will automatically direct requests to still-functioning nodes.
Architectural Overview
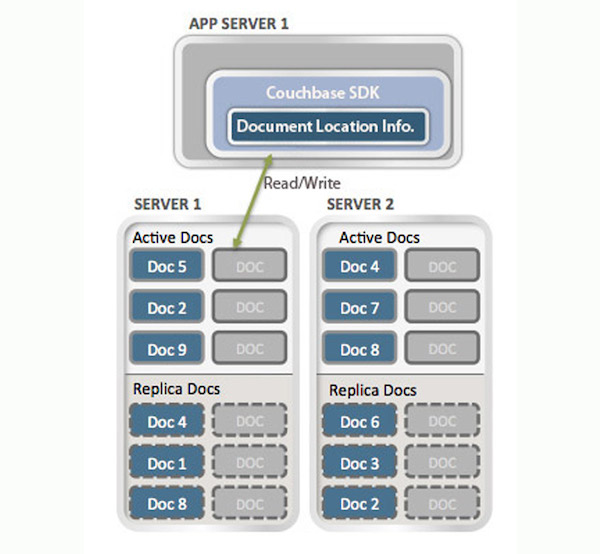
Like other NOSQL technologies, Couchbase is built from the ground up on a highly distributed architecture, with data sharded across machines in a cluster.
In a typical setting, a Couchbase DB resides in a server clusters involving multiple machines. Client library will connect to the appropriate servers to access the data.
To facilitate horizontal scaling, Couchbase uses hash sharding, which ensures that data is distributed uniformly across all nodes. The system defines 1,024 partitions (a fixed number), and once a document’s key is hashed into a specific partition, that’s where the document lives. In Couchbase Server, the key used for sharding is the document ID, a unique identifier automatically generated and attached to each document. Each partition is assigned to a specific node in the cluster. If nodes are added or removed, the system rebalances itself by migrating partitions from one node to another.
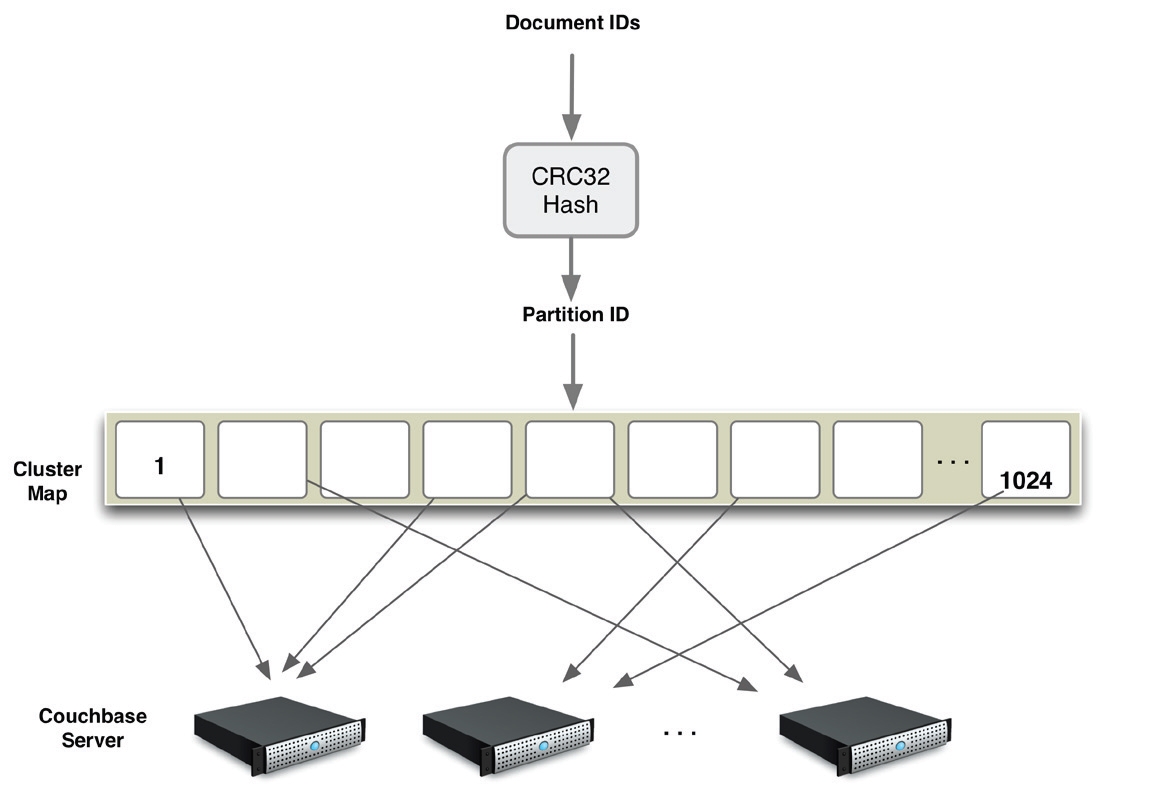
There is no single point of failure in a Couchbase system. All partition servers in a Couchbase cluster are equal, with each responsible for only that portion of the data that was assigned to it. Each server in a cluster runs two primary processes: a data manager and a cluster manager. The data manager handles the actual data in the partition, while the cluster manager deals primarily with intranode operations.
System resilience is enhanced by document replication. The cluster manager process coordinates the communication of replication data with remote nodes, and the data manager process supervise the replica data being assigned by cluster to the local node. Naturally, replica partitions are distributed throughout the cluster so that the replica copy of a partition is never on the same physical server as the active partition.
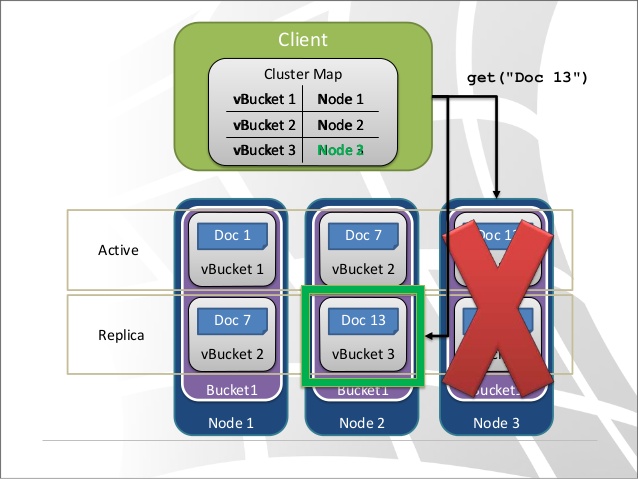
Documents are placed into buckets, and documents in one bucket are isolated from documents in other buckets from the perspective of indexing and querying operations. When a new bucket is created, it is possible to configure the number of replicas (up to three) for that bucket. If a server crashes, the system will detect the crash, locate the replicas of the documents that lived on the crashed system, and promote them to active status. The system maintains a cluster map, which defines the topology of the cluster, and this is updated in response to the crash.
Note that this scheme relies on thick clients embodied in the API libraries that applications use to communicate with Couchbase. Thick clients are in constant communication with server nodes. They fetch the updated cluster map, then reroute requests in response to the changed topology. In addition, they participate in load-balancing requests to the database. The work done to provide load balancing is actually distributed among the clients.
Changes in topology are coordinated by an orchestrator, which is a server node elected to be the single arbiter of cluster configuration changes. All topology changes are sent to all nodes in the cluster; even if the orchestrator node goes down, a new node can be elected to that position and system operation can continue uninterrupted.
Querying data
There are two patterns for querying data from Couchbase. The most efficient one is via key pattern. If the key of the document is known, the complexity of retrieval of the documents is O(1). It is also possible to retrieve multiple documents using multi-get. Using batch retrieval is very efficient when the client need to deal with a list of documents, because the number of client round-trip calls is reduced.
Another pattern of querying a Couchbase Server is performed via “views,” Couchbase terminology for indexes. Views are the mechanism used to query Couchbase data. To define a view, you build a specific kind of document called a design document which holds the JavaScript code that implements the map reduce operations that create the view’s index. Design documents are bound to specific buckets, which means that queries cannot execute across multiple buckets. Couchbase’s “eventual consistency” plays a role in views as well. If you add a new document to a bucket or update an existing document, the change may not be immediately visible.
Query parameters offer further filtering of an index. For example, you can use query parameters to define a query that returns a single entry or a specified range of entries from within an index.
Couchbase indexes are updated incrementally. That is, when an index is updated, it’s not reconstructed. Updates only involve those documents that have been changed or added or removed since the last time the index was updated. You can configure an index to be updated when specific circumstances occur. For example is possible to have the view updated based on a time interval or when a number of documents have updated.
Performance
Performance should be measured for meaningful workloads. This can help to understand performance characteristics for certain situations and choose the right NoSQL technology.
One of the benchmarks conducted to compare NoSQL technologies is called: YCSB (Yahoo Cloud Serving Benchmark). Its purpose is to focus on databases and on performance. It is open-source, extensible, has rich selection of connectors for various database technologies, it is reproducible and compares latency vs throughput.
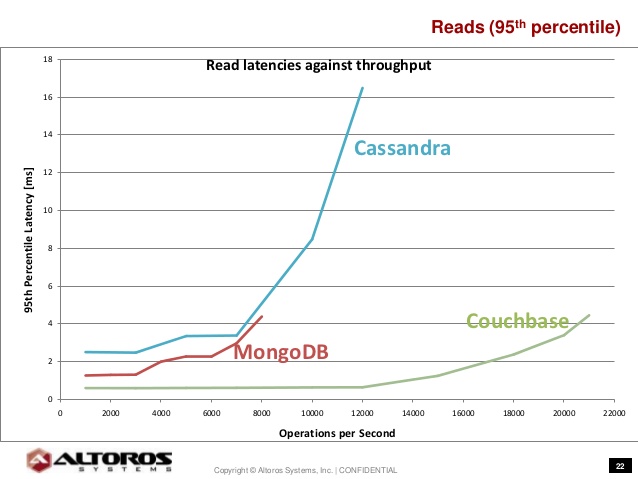
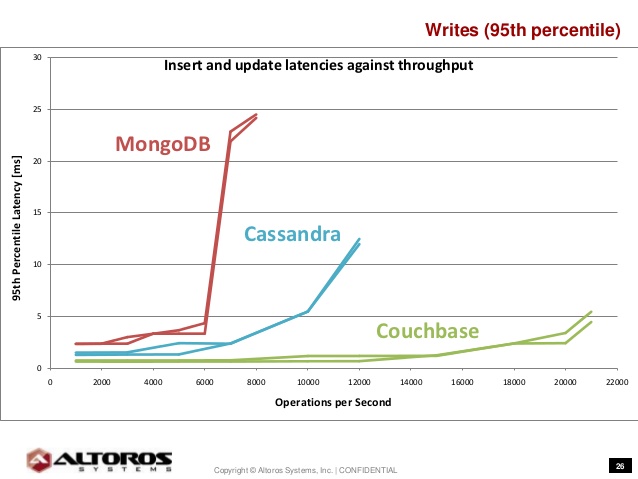
The results showed that Couchbase has the lowest latencies and the highest throughput.
Performance and consistency
To ensure consistency, it is important to execute the read/write operations on the primary nodes only. The NoSQL solutions which have only one primary node are limited from the performance point of view, because clients cannot leverage secondary nodes. The first alternative is to execute read operations on all nodes (primary and secondary). In that case, read performance is better, but no longer consistent because replication is asynchronous by default. The second alternative is synchronous replication. Which leads to consistent data, but performance degradation.
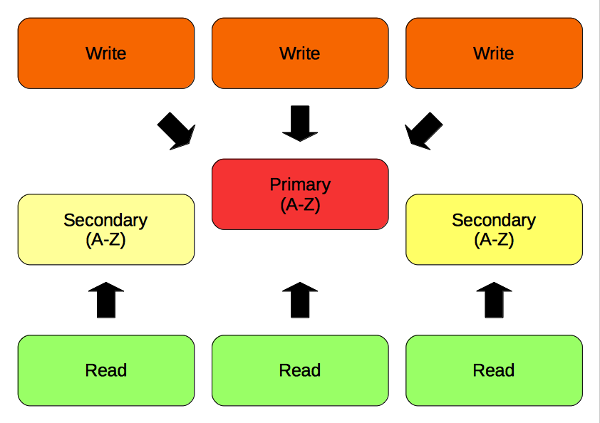
Compared to the fist approach, Couchbase Server ensures data consistency, too. It also performs read/write operations on the primary nodes only to keep the data consistent. The only difference is that it leverage all the nodes, because every node is a primary node (for a subset of partitioned data).
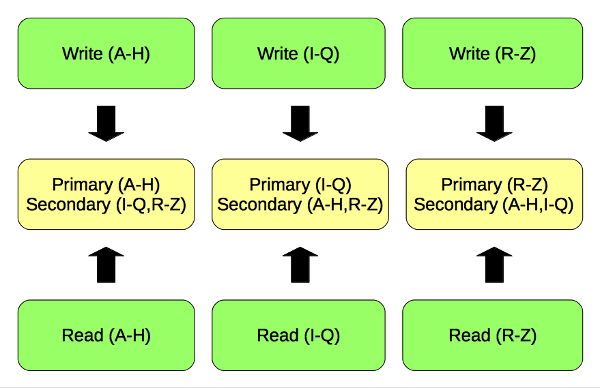
All the read/write operations are performed on the primary nodes.
Monitoring
Couchbase Server incorporates a complete set of statistical and monitoring information. The statistics are provided through all of the administration interfaces. Within the Web Administration Console, a complete suite of statistics are provided, including built-in real-time graphing and performance data.
The statistics are divided into a number of groups, allowing you to identify different states and performance information within your cluster:
- By Node - Node statistics show CPU, RAM and I/O numbers on each of the servers and across your cluster as a whole.
- By vBucket - The vBucket statistics show the usage and performance numbers for the vBuckets used to store information in the cluster.
- By View - View statistics display information about individual views, including the CPU usage and disk space used so that you can monitor the effects and loading of a view on Couchbase nodes.
- By Disk Queues - monitor the queues used to read and write information to disk and between replicas. Can be helpful in determining whether the cluster should expand to reduce disk load.
Real World Use Cases
Real-time user activity
Consume a user activity feed from a messaging system (Kafka) and store activity metrics in Couchbase. The service is capable of answering, in real time, questions like: when the user was active last time? Has the user ever played a game? All queries can be executed very fast. Based on this kind of real-time answers, the application is capable of targeting various type of users for business-related flows.
Keep user preferences
Store various user preferences across all the web products in Couchbase. This is an alternative to keeping user data in HTTP sessions, cookies or relational databases.
Promotions Management and tracking
Management of promotions which attracts customers to try various products based on predefined qualifying criteria. The customer promotion progress is tracked as well. The system is capable to identify in real-time if a customer has succesfully fulfilled a promotion and awards the configured reward.
Conclusion
Explosive growth in Internet usage, the increasing amount of data handled by modern application, the changing nature of data required to be incorporated require a detailed analysis when deciding the technology to use for data storage. Choosing a NoSQL can be a good decision when applications require a flexible data model, support a large number of concurrent users, scalability and performance are important to cope with business requirements. Couchbase is an important player in NoSQL world. It works very well for high load reads and writes, with great built in caching and solid scale up and scale down model. The Couchbase architecture makes it possible to provide consistency and outstanding performance at the same time. It performs very well compared to other similar technologies based on real-world benchmarks. Though it is not a silver bullet, and does not excel in every possible area, it can be a perfect match for several types of applications.
Resources
- RDBMS vs NoSQL
- Couchbase Server Architecture Review
- Betfair plus Couchbase
- Couchbase blows competition
- Couchbase performance benchmarking
- No SQL performance series
- 10 enterprise usecases for Couchbase
- MongoDB vs Coucbase showdown